import time
print(time.time())
print(time.localtime())print(time.strftime('%Y-%m-%d %X',time.localtime()))
绘图显示中文配置


import matplotlib.pyplot as plt
a = [1,1,2,3]
b = [2,2,2,2]plt.plot(a,b)plt.title("天生自然")plt.show()
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\taobao_data.csv")
print(df.head())
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\taobao_data.csv",delimiter=",",encoding="utf8",header=0)
print(df.head())
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\taobao_data.csv",delimiter=",",encoding="utf8",header=0)
df.to_csv("E:\\temp\\taobao_price_data.csv", columns=["宝贝","价格"],index=False,header=True)import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\taobao_data.csv",delimiter=",",encoding="utf8",header=0)
print(df[0:3])
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\taobao_data.csv",delimiter=",",encoding="utf8",header=0)
cols = df[["宝贝","价格"]]print(cols.head())
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\taobao_data.csv",delimiter=",",encoding="utf8",header=0)
a = df.ix[0:3,["宝贝","价格"]]print(a)
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\taobao_data.csv",delimiter=",",encoding="utf8",header=0)
df["销售量"] = df["价格"]*df["成交量"]print(df.head())
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\taobao_data.csv",delimiter=",",encoding="utf8",header=0)
a = df[(df["价格"]<100)&(df["成交量"]<10000)]print(a)
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\taobao_data.csv",delimiter=",",encoding="utf8",header=0)
print(df.head())df1 = df.set_index("位置")print(df1.head())df2 = df1.sort_index()print(df2.head())
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\taobao_data.csv",delimiter=",",encoding="utf8",header=0)
df1 = df.set_index(["位置","卖家"])print(df1.head())
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\taobao_data.csv",delimiter=",",encoding="utf8",header=0)
df1 = df.set_index(["位置","卖家"]).sortlevel(0)print(df1.head())
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\taobao_data.csv",delimiter=",",encoding="utf8",header=0)
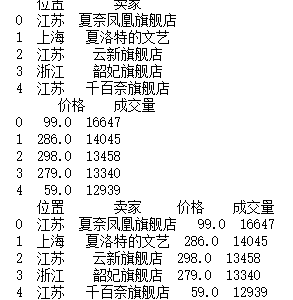
a = df.drop(["宝贝","卖家"],axis=1)print(a.head())b = df.drop(["宝贝","卖家"],axis=1).groupby("位置")
print(b.head())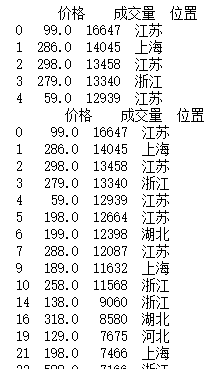
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\taobao_data.csv",delimiter=",",encoding="utf8",header=0)
a = df.drop(["宝贝","卖家"],axis=1).groupby("位置").mean()print(a.head())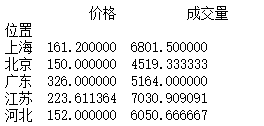
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\taobao_data.csv",delimiter=",",encoding="utf8",header=0)
a = df.drop(["宝贝","卖家"],axis=1).groupby("位置").mean().sort_values("成交量",ascending=False)print(a.head()) 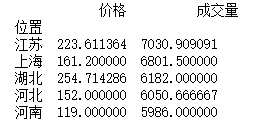
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\taobao_data.csv",delimiter=",",encoding="utf8",header=0)
a = df.drop(["宝贝","卖家"],axis=1).groupby("位置").sum().sort_values("成交量",ascending=False)print(a.head())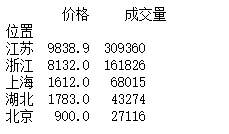
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\taobao_data.csv",delimiter=",",encoding="utf8",header=0)
print(df.info())
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\taobao_data.csv",delimiter=",",encoding="utf8",header=0)
print(df.describe())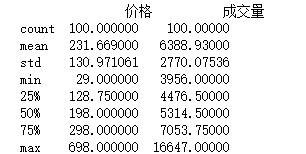
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\taobao_data.csv",delimiter=",",encoding="utf8",header=0)
print(df.describe(include=["object"]))
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\taobao_data.csv",delimiter=",",encoding="utf8",header=0)
a = df["成交量"].groupby(df["位置"])print(a.head())
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\taobao_data.csv",delimiter=",",encoding="utf8",header=0)
a = df["成交量"].groupby(df["位置"]).mean()print(a.head())
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\taobao_data.csv",delimiter=",",encoding="utf8",header=0)
a = df["成交量"].groupby([df["位置"],df["卖家"]]).mean()print(a.head())
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\taobao_data.csv",delimiter=",",encoding="utf8",header=0)
a = df.groupby("位置").mean()print(a.head())
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\taobao_data.csv",delimiter=",",encoding="utf8",header=0)
a = df.groupby(["位置","卖家"]).mean()print(a.head())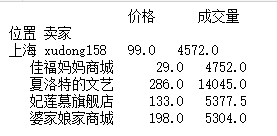
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\taobao_data.csv",delimiter=",",encoding="utf8",header=0)
a = df.groupby(["位置","卖家"]).size()print(a.head())
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\taobao_data.csv",delimiter=",",encoding="utf8",header=0)
a = df[30:35][["位置","卖家"]]print(a)b = df[90:95][["卖家","成交量"]]
print(b)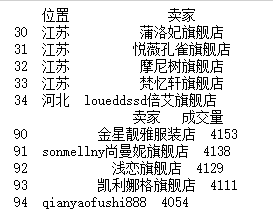
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\taobao_data.csv",delimiter=",",encoding="utf8",header=0)
a = df[30:35][["位置","卖家"]]b = df[30:35][["卖家","成交量"]]c = pd.merge(a,b)print(c)
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\taobao_data.csv",delimiter=",",encoding="utf8",header=0)
a = df[30:35][["位置","卖家"]]b = df[30:35][["卖家","成交量"]]c = pd.merge(a,b,on="卖家")print(c)
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\taobao_data.csv",delimiter=",",encoding="utf8",header=0)
a = df[10:20][["位置","卖家"]]b = df[30:40][["卖家","成交量"]]c = pd.merge(a,b,how="outer")print(c)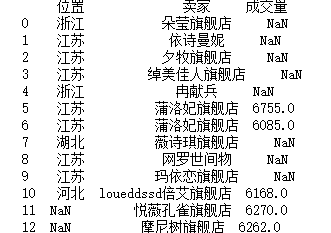
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\taobao_data.csv",delimiter=",",encoding="utf8",header=0)
a = df[10:20][["位置","卖家"]]b = df[30:40][["卖家","成交量"]]c = pd.merge(a,b,how="left")print(c)
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\taobao_data.csv",delimiter=",",encoding="utf8",header=0)
a = df[10:20][["位置","卖家"]]b = df[30:40][["卖家","成交量"]]c = pd.merge(a,b,how="right")print(c)
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\taobao_data.csv",delimiter=",",encoding="utf8",header=0)
a = df[:10][["位置","卖家"]]print(a)b = df[:10][["卖家","成交量"]]print(b)c = pd.merge(a,b,how="right")print(c)
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\taobao_data.csv",delimiter=",",encoding="utf8",header=0)
a = df[:10][["位置","卖家"]]b = df[:10][["卖家","成交量"]]c = pd.merge(a,b,left_index=True,right_index=True)print(c)
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\taobao_data.csv",delimiter=",",encoding="utf8",header=0)
a = df[:10][["位置","卖家"]]b = df[:10][["价格","成交量"]]c = pd.merge(a,b,left_index=True,right_index=True)print(c)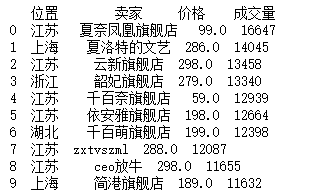
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\taobao_data.csv",delimiter=",",encoding="utf8",header=0)
a = df[:10][["位置","卖家"]]b = df[:10][["价格","成交量"]]c = a.join(b)print(c)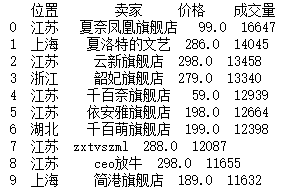
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\taobao_data.csv",delimiter=",",encoding="utf8",header=0)
a = df[:5]["宝贝"]b = df[5:10]["宝贝"]c = df[10:15]["宝贝"]d = pd.concat([a,b,c])print(d)
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\taobao_data.csv",delimiter=",",encoding="utf8",header=0)
a = df[:5]["宝贝"]print(a)b = df[:5]["价格"]print(b)c = df[:5]["成交量"]print(c)d = pd.concat([a,b,c],axis=1)print(d)
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\taobao_data.csv",delimiter=",",encoding="utf8",header=0)
a = df[:5][["位置","卖家"]]print(a)b = df[:5][["价格","成交量"]]print(b)c = pd.concat([a,b])print(c)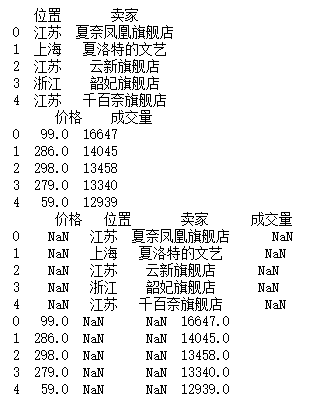
import pandas as pd
df = pd.read_csv("F:\\python3_pachongAndDatareduce\\data\\pandas data\\taobao_data.csv",delimiter=",",encoding="utf8",header=0)
a = df[:5][["位置","卖家"]]print(a)b = df[:5][["价格","成交量"]]print(b)c = pd.concat([a,b],axis=1)print(c)